
Companies that adopt data warehouse (DWH) solutions benefit from having their key data aggregated in a centralized repository, immediate access to strategic and operational insights that drive key business decision making & a single version of truth across their enterprise. An end-to-end DWH solution will require a data integration and transformation tool, a data storage tool, an orchestration tool, and a business intelligence (BI) tool for customized dashboards.
Depending on the size and estimated growth of the enterprise, the volume of the data to be handled, and the number of dashboards to be created, the cost of implementing and maintaining a DWH solution can range from tens of thousands of dollars to millions of dollars. For on-prem based DWH solutions, the license costs for enterprise grade data integration, data warehouse storage and business intelligence tools, and the underlying infrastructure, can easily add up to thousands of dollars per year. Cloud based pay as you go solutions start to become very costly when the company’s data volumes increase. This also ties the company to a single cloud-based vendor.
For small to mid-sized companies these cumulative costs for a DWH can appear to be prohibitive, as businesses leaders will compare them to the direct benefits of investing an equivalent amount in purchasing additional raw materials, updating their machinery, hiring talented workers, expanding their sales network, renting new warehouses, etc. The perceived Return on Investment (RoI) makes it hard for such companies to justify building an enterprise DWH.
To address this challenge for rapidly growing small to mid-sized companies, Prescience, a movate company Decision Solutions has created a cloud-agnostic enterprise DWH solution which is completely built on free to use open-source tools. This solution is scalable and can efficiently handle any increase in the data volumes. Building a DWH solution on open-source tools gives organizations the flexibility to build and adapt their enterprise tool stack based on evolving business and IT requirements.
Solution Overview
The Prescience, a movate company open-source enterprise DWH solution consists of a data integration tool, a data transformation tool, a database tool, a task orchestration tool, and a business intelligence tool.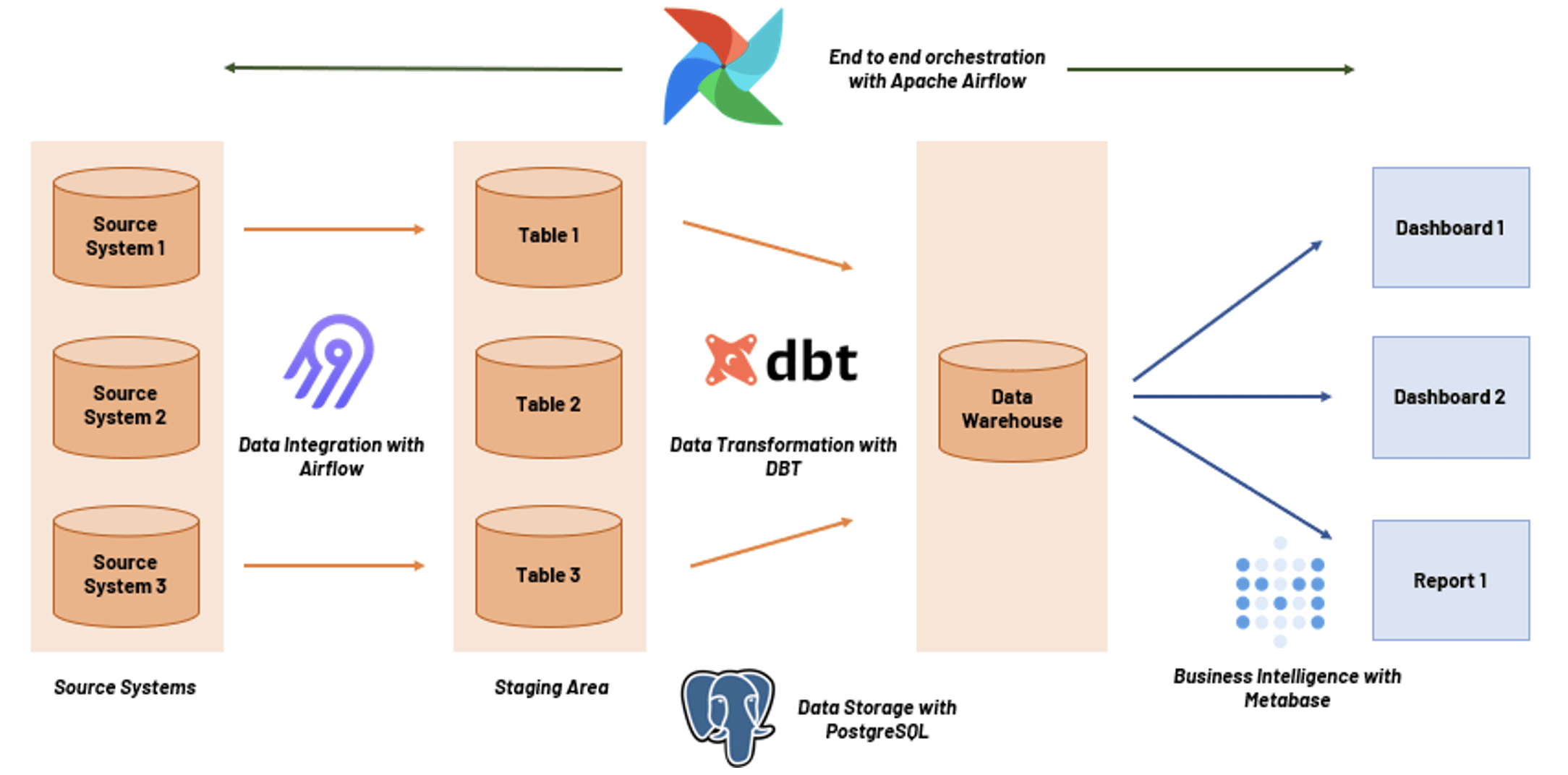
The technologies used for building this enterprise DWH solution are,
- Airbyte for Data Integration
Airbyte provides a wide range of pre-built connectors and allows creation of custom connectors for all unsupported data sources. - PostgreSQL for Data Storage
PostgreSQL is an advanced relational database that supports both SQL (relational) and JSON (non-relational) querying. It supports writing functions using SQL, Perl, Python, Java, shell, JavaScript etc. It provides proven authentication and access control mechanisms. - DBT (Data Build Tool) for Data Transformation
DBT supports SQL-based transformations and allows for the creation of complex data models. It also provides features like version control and testing for ensuring data quality. - Metabase for Business Intelligence
Metabase connects directly to the data in PostgreSQL, allowing users to create, share, and visualize data insights without writing complex code. Its user-friendly interface makes it easy to generate reports and dashboards for end business users and top management. - Apache Airflow for Task Orchestration
Apache Airflow provides scheduling, task dependency management, error handling and retry mechanisms. It also supports monitoring through a web interface and integration with external tools.
Proof of Concept
The Prescience, a movate company team considered the example of a growing retail chain to develop a fully functional Proof of Concept (PoC) on this open-source DWH. The company needed to thoroughly analyze their data sets using only open-source tools, as they are looking to minimize their annual IT costs, while focusing on overall profitability and store expansion. The transactional sales data, existing inventory, and customer feedback was available in different IT applications. The company’s target was to leverage insights from this data to streamline their business operations, reduce their operational costs and enhance overall customer satisfaction ratings.
Below are the key facets of the open-source DWH solution built by Prescience, a movate company.
- Seamless Data Transfer with Airbyte
Since all the retail chain’s data resided in different source systems, we built an Airbyte data pipeline to transfer this historical data to the Staging Layer on the PostgreSQL instance. Airbyte’s pre-built connector for PostgreSQL was configured to enable the easy extraction of historical data and the loading of incremental daily data, on an ongoing basis. This configuration ensured that the downstream data transformation pipeline always received up-to-date data without the need for manual intervention. - Simplified Data Storage with PostgreSQL
PostgreSQL is mostly used in Online Transaction Processing (OLTP) applications, but it can also be used for Online Analytical Processing (OLAP) use cases. It is open source, well supported by a huge developer community, highly secure, supports data encryption, can manage big data and has been deployed in millions of servers worldwide. Considering these, PostgreSQL has been used for both the Staging Layer and the DWH layer. - Streamlined Data Transformation with DBT
DBT was used to perform comprehensive transformations on the data in the Staging Layer before storing it in the DWH. These data transformations included a range of operations such as aggregation, deduplication, cleansing, and data joining. By structuring these transformations using SQL-based queries within DBT, the data in the DWH was aggregated and transformed in the required format. DBT’s features such as version control and testing ensured the reliability and maintainability of the transformation logic. - Insightful Data Visualization with Metabase
Using Metabase, different dashboards and reports were created to empower business stakeholders with actionable insights. These dashboards and reports covered Key Performance Indicators (KPIs) related to the company’s distribution efficiency, waste reduction, and customer satisfaction. With Metabase’s interactive dashboards and reporting capabilities, business users can easily explore trends, identify anomalies, and make informed decisions to drive operational excellence.Here is a sample dashboard created as part of the PoC.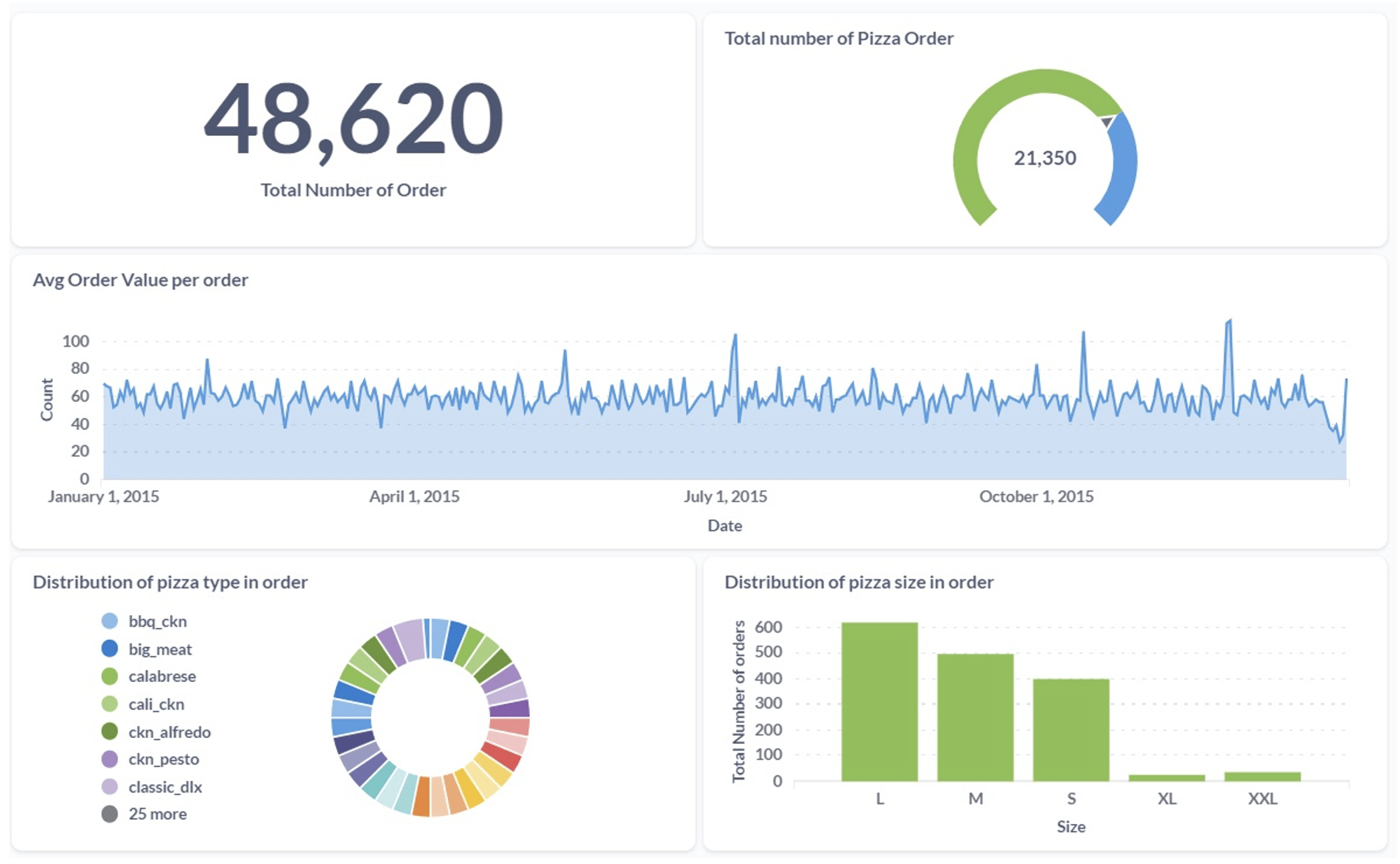
Figure: Sample Dashboard - Pipeline Orchestration & Management with Apache Airflow
Apache Airflow orchestrated the data flow by seamlessly integrating the data ingestion, transformation, and visualization stages. By defining Directed Acyclic Graphs (DAGs), Airflow organized and scheduled the execution of tasks, ensuring data flowed uninterrupted through the pipeline. The dependencies between tasks were configured to orchestrate the sequence of operations.
Additionally, Airflow’s error handling and retry mechanisms provided resilience to the overall pipeline, automatically handling failures, and ensuring data integrity. The intuitive web interface of Airflow facilitated monitoring and management of pipeline activities, allowing for real-time tracking of task execution and performance metrics.
Conclusion
This comprehensive DWH solution using open-source tools helps our clients to benefit from adopting a highly cost-effective approach without compromising on their required functionalities, reliability, and data security. This setup not only meets a client’s objectives of improving distribution efficiency, minimizing cost, and enhancing customer satisfaction but also demonstrates the viability and value of leveraging open-source technologies for enterprise data management and analytics initiatives.
If you are looking for a starting point for your business, take advantage of our personalized FREE consultation workshop Sign up here.
Subscribe for regular updates on AI and Data Innovations, case studies, and blogs. Join our mailing list.

Ganesh Lungade is a Senior Data Engineer at Prescience Decision Solutions. In this role, he specializes in aiding clients in building robust, high-performance, and scalable data infrastructures on both AWS and Azure platforms. Ganesh excels in crafting effective ETL (Extract, Transform, Load) processes for large-scale datasets, ensuring efficient data management and processing.


