
A Large Language Model (LLM) is a type of Artificial Intelligence (AI) that uses deep learning techniques to understand, generate, and manipulate human language. These models are trained on vast amounts of text data, enabling them to create coherent and contextually relevant responses. They excel in tasks like language translation, text summarization, sentiment analysis, image and video creation, as well as conversational AI.
For enterprise and business users, it can be quite frustrating to receive unsatisfactory LLM responses such as “I don’t know” or those that are incorrect. Sometimes, LLMs can generate plausible-sounding but incorrect information, a phenomenon known as hallucination. These occur because traditional LLMs lack access to comprehensive, domain-related data sources, as well as confidential and up-to-date information related to their company.
For these users to harness the full power of these otherwise static LLMs, they need to query their domain and company data to receive contextual responses tailored to their queries. The traditional process of constantly training and retraining these models with relevant enterprise data, followed by parameter tuning, is very expensive and time-consuming.
This problem can be mitigated by adopting the Retrieval-Augmented Generation (RAG) architecture. This RAG approach enhances the efficacy of LLM applications by automatically retrieving updated data from enterprise documents and data sources. Unlike regular LLMs which are limited by their training data, the RAG approach incorporates a retrieval system that fetches real-time enterprise information from its knowledge database, thereby ensuring that the LLM responses are current and contextually precise.
Key Components of RAG Architecture
The two major components of the RAG Architecture are
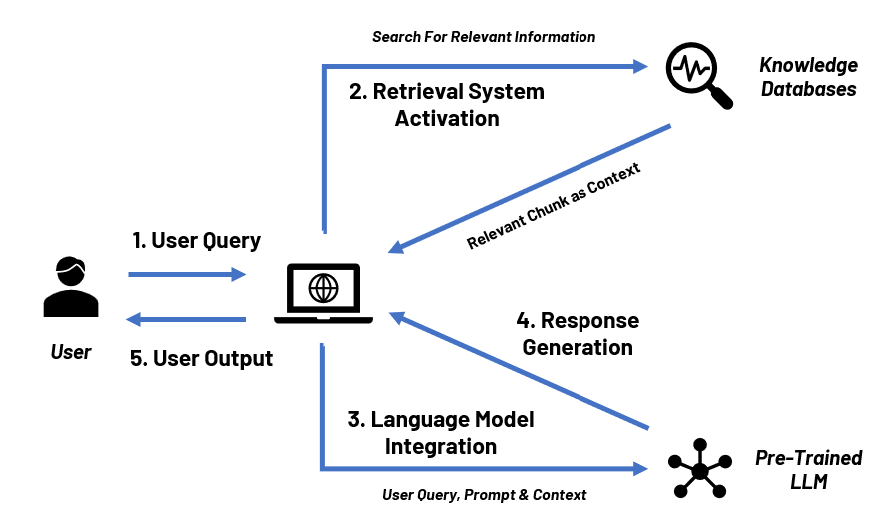
- Retrieval System: Based on the user’s query, this component searches for relevant chunks of data from the knowledge database. In most RAG applications, a vector database (e.g., ChromaDB, Milvus, Pinecone, etc.) is used as the knowledge base. This knowledge database incorporates data from all the required in house applications and data files.
- Large Language Model: The processed information is fed into an LLM, such as GPT-4, with a prompt as context. This model integrates the new information with its pre-existing knowledge to generate a response.
Overview of the RAG Process
The different steps involved in the RAG process are:
- User Query: This happens when a user submits a query or question to the LLM.
- Retrieval System Activation: The retrieval system searches through the updated knowledge databases to find documents and data relevant to the user query.
- Large Language Model Integration: The relevant new information from these knowledge databases is combined with the language model’s existing knowledge base and prompt.
- Response Generation: The language model generates a response that incorporates both the retrieved information and its own understanding of the topic.
- User Output: The solution provides the user with a correct and relevant response.
Illustrative Example of RAG based LLM
Let’s say that a market research analyst wants to know the revenue from the worldwide sales of all iPhones in 2023. Since Apple is a publicly traded company, this data is published annually in their 10-K form. However, this specific information is not part of the training data for publicly available LLMs. So, how can the market research analyst get answers to such queries on sales figures? One option is to manually go through the entire 10-K form for 2023 to extract the required data points. Alternatively, the analyst can implement a RAG architecture-based LLM that has 10-K forms stored in its knowledge base.

In contrast, a RAG based system will retrieve the relevant section from Apple’s 10-K form and other financial documents stored in its knowledge database. This retrieval system will pull up the exact sales data for the iPhones in 2023, as shown below.

Challenges in Implementing RAG Architecture
While the RAG architecture presents several benefits to businesses, there are certain constraints that companies must deal with during the project implementation.
- Hallucination:
- Risk of Data Breach:
- Finding Relevant Chunks:
- Computational Costs:
- Latency and Response Time:
- Maintaining Data Freshness:
Use Cases for RAG Architecture
- Customer Support: The implementation of the RAG approach provides instant, precise responses to customer queries, thereby enhancing the support efficiency and overall customer satisfaction.
- Healthcare: The RAG architecture assists in retrieving the latest medical research and patient records, thereby improving diagnostic accuracy and treatment recommendations.
- Legal: The RAG system helps in quickly searching through thousands of legal documents and case precedents, thereby streamlining research and case preparation.
- Compliance: This architecture helps companies identify, manage and adhere to complex state and national regulatory and compliance norms.
- Financial Services: The RAG architecture offers up-to-date financial data and analysis, thus aiding in investment decisions and risk management.
- Marketing & Advertising: RAG systems can create high-quality, contextually relevant articles, social media content and ads for marketing agencies.
Conclusion
Thus, Retrieval-Augmented Generation (RAG) architecture has revolutionized AI capabilities by integrating enterprise data points with LLMs to ensure highly accurate and up-to-date responses to user queries. By seamlessly combining real-time domain and company data, these RAG based LLMs are helping hundreds of companies to easily & effectively enhance their decision making in sales, marketing, supply chain, customer support, advertising, finance, human resources (HR), legal, and other business services.
If you are looking for a starting point for your business, take advantage of our personalized FREE consultation workshop Sign up here.
Subscribe for regular updates on AI and Data Innovations, case studies, and blogs. Join our mailing list.

Aditya is a ML engineer specializing in Machine Learning, Deep Learning, and the latest advancements in LLM technology. In his free time, he enjoys playing computer games, singing, and exploring new technologies and fascinating facts.


