The company runs a large online auction platform and shopping website that connects buyers and sellers in over 190 countries. Their website has millions of sellers with 1.9 billion global listings and over 132 million active buyers.
THE CHALLENGE
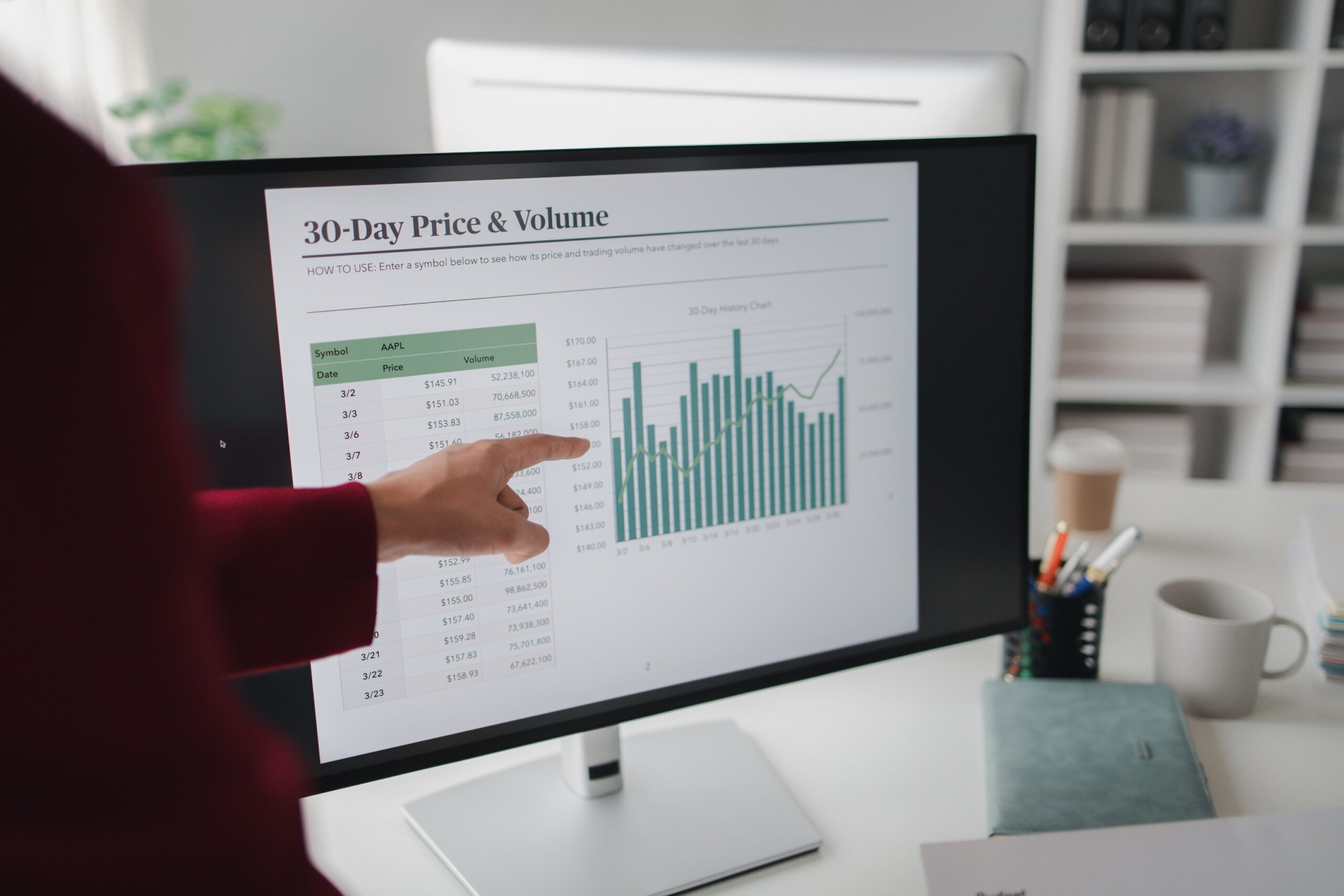
For compliance purposes, the company has to prepare a consolidated document which contains the details of all its global tax liabilities. An existing application collects data from different source systems and prepares a PDF file with all the details required by the Internal Revenue Service (IRS). Within this file, there are 13 different taxation formats which capture all the details, in a file format which will be accepted by the IRS.
Due to their worldwide operations, the size of the combined PDF file can range from between 4,000 to 5,000 pages. This document length changes from year to year based on the number of applicable line entries for each of the different taxation formats. Since the overall file length was not constant, the taxation formats involve variable entries and the file size was massive, there was no existing third party tool or process which allowed for easy extraction of the data for automated reconciliation.
Once the PDF file is generated, the company’s business users have to manually scan through each page of the document and reconcile the tax figures by comparing them against what is stored in the source systems. This validation process requires multiple employees to spend between 1 – 2 weeks for individually reconciling every line item in the document. Data quality issues arise due to multiple data sources, exchanging source data in Excel files and country specific taxation laws. When discrepancies are found, users identify the cause and get the application to generate the PDF with the updated details. However, if there are any unidentified mismatches in the calculated tax liabilities, then the company will pay higher taxes to the IRS.
The company needed an automated process which would extract all the mandatory taxation information from the PDF file, while also avoiding the possibility of errors arising out of manual oversight during reconciliation.
THE SOLUTION
The team of business analysts and data scientists from Prescience Decision Solutions, a Movate company studied the PDF reports from the past few years to understand the nature of the files and the different applicable taxation formats for the IRS. Based on this, the overall solution was designed comprising of
– Stage 1: Pre-Processing
– Stage 2: Optical Character Recognition (OCR)
– Stage 3: Post Processing
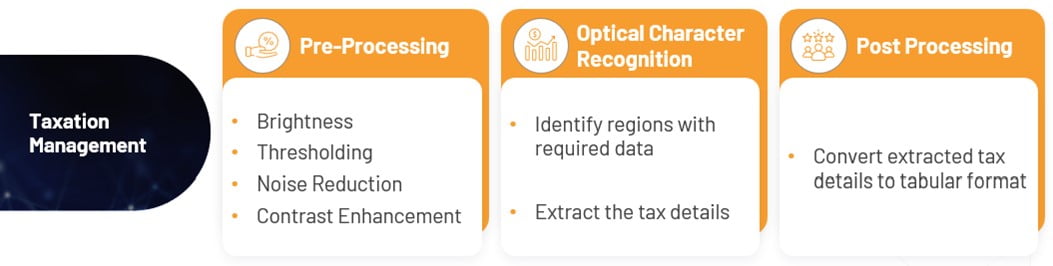
In the Pre-Processing Stage, the team evaluates the generated PDF file to confirm whether it can be directly processed by the overall solution. If the file needs to be enhanced, then the team configures various parameters such as the contrast, noise, brightness, thresholding etc, to make
the PDF document suitably prepared for the OCR stage. The tools used in this Pre-Processing stage are PyPDF and OpenCV.
In the OCR Stage, the solution scans the entire PDF file and through key word identification, finds which pages are relevant. On each of these shortlisted pages, the solution recognizes key regions of interest which contain the expected taxation details. Based on this, the solution extracts the tax numbers from that portion of the page. The tools used in this OCR stage are Tesseract, EasyOCR and Tabulate.
In the Post Processing Stage, the solution saves the extracted tax figures in a tabular format which can be opened in Excel. The tool used in this Post Processing stage is Python.
Once the data is published in the Excel file, the company’s business users run scripts to automate the comparison of the tax details in the PDF file with the data present in the source systems. When errors are immediately identified, the PDF file is republished with the required corrections.
THE IMPACT
The taxation management solution has directly resulted in over 96% effort reduction for tax data reconciliation. Going forward, for all taxation submissions, the total execution time including Pre-Processing, OCR and Post-Processing, will be less than 1 business day. This solution can
extract all the taxation information from the 4000 to 5000-page file with an accuracy rate of over 95%. Since it is built on all open-source tools, the company does not incur any additional license costs.
Overall, this solution has directly resulted in substantial cost savings, and also removed the risk of possible manual oversights leading to higher tax payments to the IRS.